



Aggregation is one of the most important concepts of MongoDB. It is complicated as well. I will try to explain to you a few basics using examples.
What is Aggregation?
Aggregations are operations in MongoDB which can be performed on collections where documents (aka objects/records) are passed through a series of stages to achieve the desired results.
Simply said, its a series of operations in order to query the data.
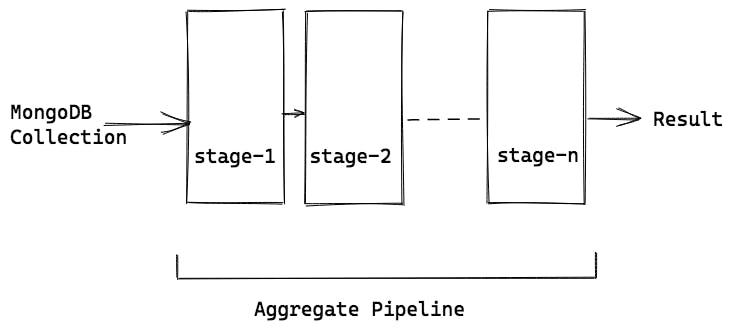
Generally, the aggregation pipeline contains a complicated computation or pulling the data from multiple collections. You’ll get more clear as we study the operations which can be done in each stage of the pipeline.
The aggregate function
You can use db.collection.aggregate() function in mongo shell in order to perform the aggregate operations.
It takes an array of objects as an argument, where each element of the array represents 1 stage of the pipeline. There are various set of operators which can be used at each stage depending upon your requirement.
Pro Tip: The sequence of operations will determine the efficiency of the overall MongoDB aggregation pipeline.
$match as a stage in aggregate
In simple words, it just filters the input documents based on a query.
Example
Let’s say posts collection has this data.
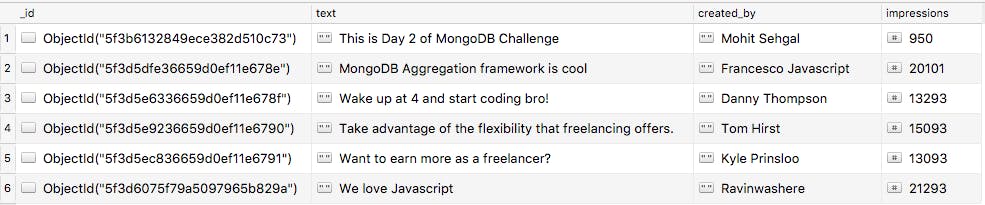
Let's find out all the posts which have more than 1000 impressions
So here goes the query and result
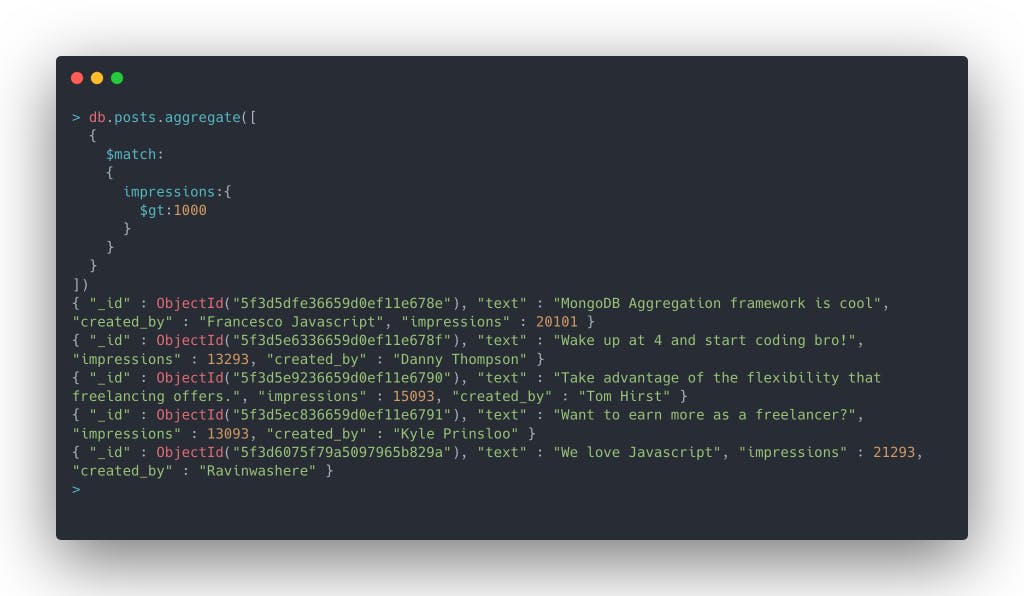
You can see that my post has been left out, cause my post had less than 1000 impressions 🙁
All the MongoDB queries which you use in db.collection.find() are compatible with $match stage.
$match can be used at any stage of the pipeline and can be used any number of times based on the requirement. The $match is one of the most used operators in aggregation pipelines.
$sort stage in pipeline
As the name suggests, this operator is used to sort the input documents based on a field/property of the documents.
Example
List all the posts which have more than 1000 impressions and sort by impressions in increasing order.
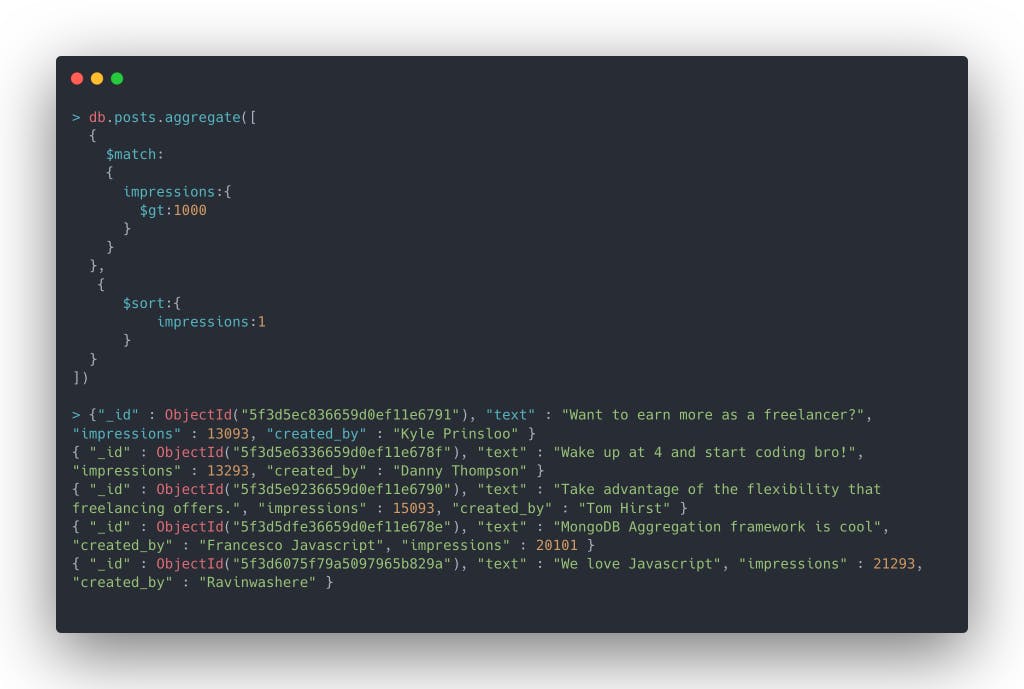
You see that in results, records are sorted according to no. of impressions in increasing order.
$skip stage in the aggregation pipeline
$skip skips the specified number of documents from the input and returns the rest of them. This is particularly helpful when you want to paginate the data at the frontend.
Its syntax is pretty simple to take a look
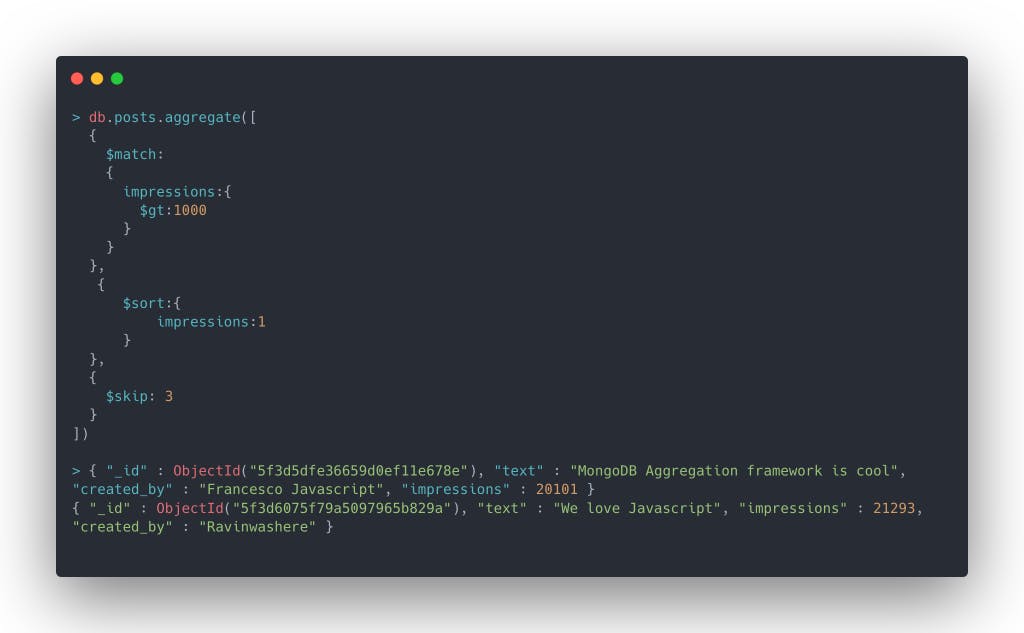
You notice, that earlier there were 5 documents, when you added {$skip:3} at the end of the pipeline, it skips the 3 and displays the remaining 2.
$count in the aggregate pipeline
It simply counts the number of documents passed as input.
Example
Let's find out the number of posts which have the impression greater than 15000
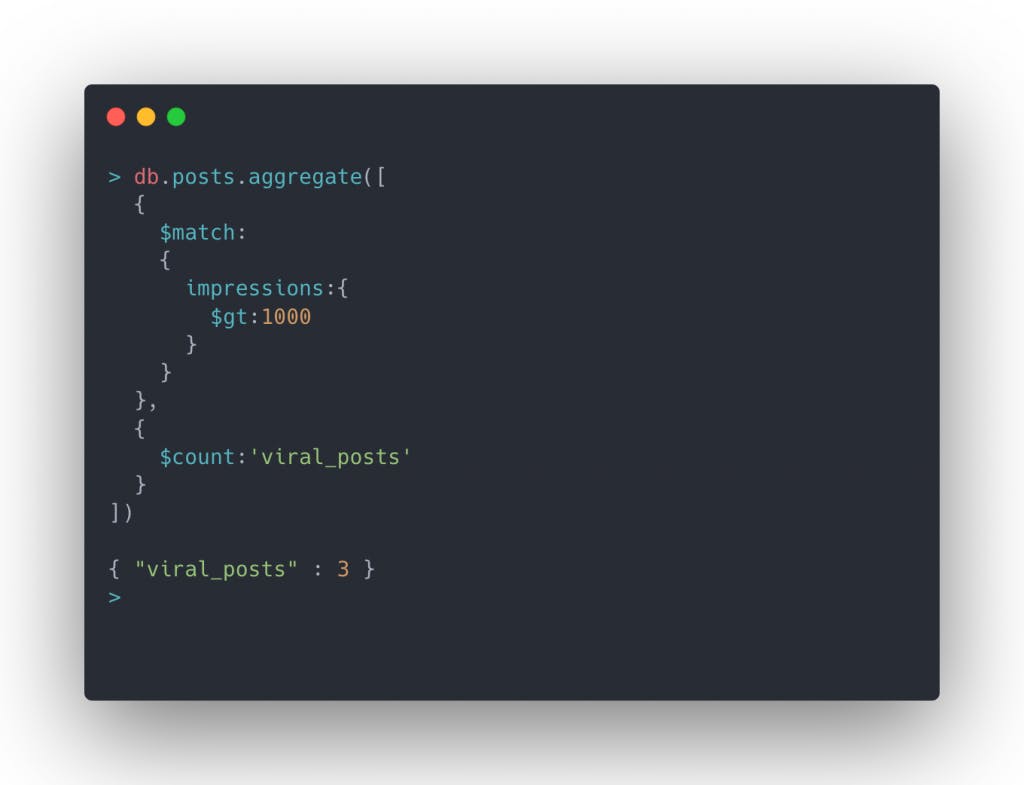
As an argument to $count, we pass the property name where the count will be stored.
Conclusion
In this post, I discussed the basics of the Aggregation pipeline in MongoDB and few basic stages like $match, $sort, $skip, $count. In upcoming posts I will take on more complex operations like $lookup, $unwind, and more.
I hope you were able to absorb the basics.
Let me know if you have any queries in the comments section or Tweet at @MohitSehgl
Originally posted on Appsyoda.com